SVM P.3 – Implementation
Subscribe to Tech with Tim
Implementing a SVM
Implementing the SVM is actually fairly easy. We can simply create a new model and call .fit() on our training data.
from sklearn import svm clf = svm.SVC() clf.fit(x_train, y_train)
To score our data we will use a useful tool from the sklearn module.
from sklearn import metrics y_pred = clf.predict(x_test) # Predict values for our test data acc = metrics.accuracy_score(y_test, y_pred) # Test them against our correct values
And that is all we need to do to implement our SVM, now we can run the program and take note of our amazing accuracy!

Wait... Our accuracy is close to 60% and that is horrible! Looks like we need to add something else.
Adding a Kernel
The reason we received such a low accuracy score was we forgot to add a kernel! We need to specify which kernel we should use to increase our accuracy.
Kernel Options:
- linear
- poly
- rbf
- sigmoid
- precomputed
We will use linear for this data-set.
clf = svm.SVC(kernel="linear")
After running this we receive a much better accuracy of close to 98%
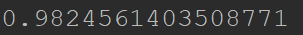
Changing the Margin
By default our kernel has a soft margin of value 1. This parameter is known as C. We can increase C to give more of a soft margin, we can also decrease it to 0 to make a hard margin. Playing with this value should alter your results slightly.
clf = svm.SVC(kernel="linear", C=2)
If you want to play around with some other parameters have a look here.
Comparing to KNearestNeighbors
If we want to see how this algorithm runs in comparison to KNN we can run the KNN classifier on this data-set and compare our accuracy values.
To change to the KNN classifier is quite simple.
from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=11) # Simply change clf to what is above
Note that KNN still does well on this data set but hovers around the 90% mark.
Full Code
import sklearn from sklearn import datasets from sklearn import svm from sklearn import metrics from sklearn.neighbors import KNeighborsClassifier cancer = datasets.load_breast_cancer() #print(cancer.feature_names) #print(cancer.target_names) x = cancer.data y = cancer.target x_train, x_test, y_train, y_test = sklearn.model_selection.train_test_split(x, y, test_size=0.2) clf = svm.SVC(kernel="linear") clf.fit(x_train, y_train) y_pred = clf.predict(x_test) acc = metrics.accuracy_score(y_test, y_pred) print(acc)