KNN P.2 – How Does it Work?
Subscribe to Tech with Tim
If you are more interested in implementing this algorithm and do not care about the math behind it proceed to the next tutorial.
How Does K-Nearest Neighbors Work?
In short, K-Nearest Neighbors works by looking at the K closest points to the given data point (the one we want to classify) and picking the class that occurs the most to be the predicted value. This is why this algorithm typically works best when we can identify clusters of points in our data set (see below).
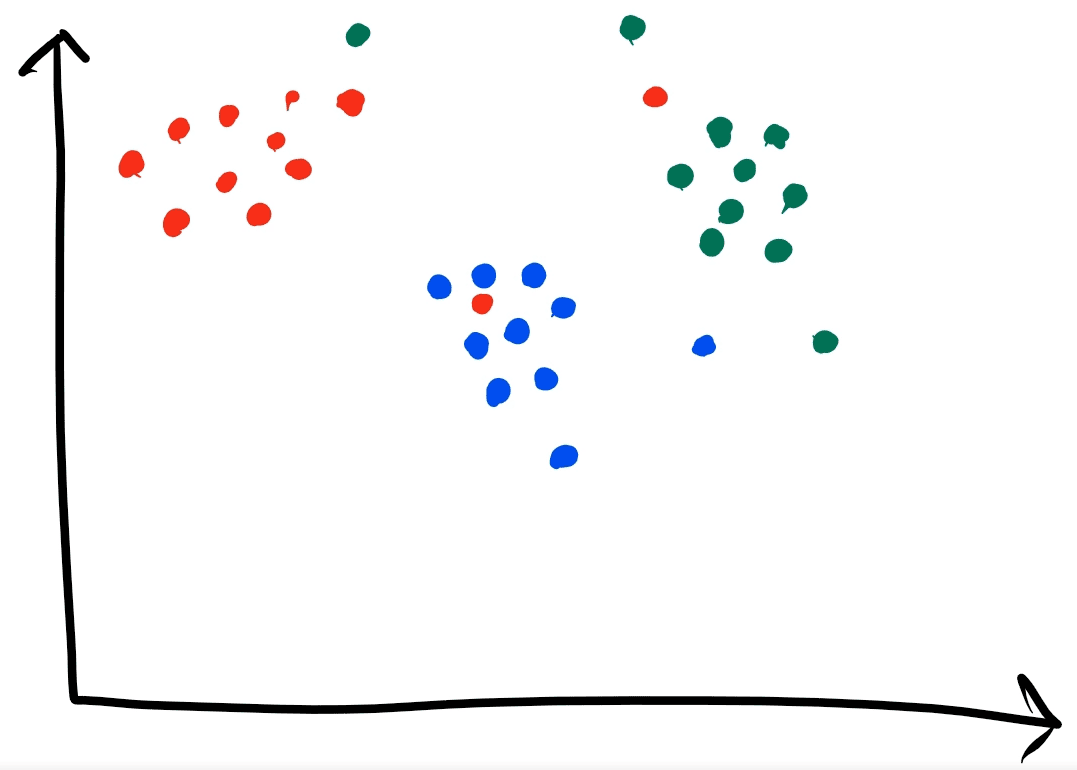
We can clearly see that there are groups of the same class points clustered together. Because of this correlation we can use the K-Nearest Neighbors algorithm to make accurate classifications.
Example
Let's have a look at the following example.

We want to classify the black dot as either red, blue or green. Simply looking at the data we can see that it clearly belongs to the red class, but how do we design an algorithm to do this?
First, we need to define a K value. This is going to be how many points we should use to make our decision. The K closest points to the black dot.
Next, we need to find out the class of these K points.
Finally, we determine which class appears the most out of all of our K points and that is our prediction.

In this example our K value is 3.
The 3 closest points to our black dot are the ones that have small black dots on them.
All three of these points are red, therefore red occurs the most. So we classify the black dot as apart of the red group.
If you'd like to see some more examples with K > 3 and more difficult cases please watch the video.
Limitations and Drawbacks
Although the KNN algorithm is very good at performing simple classification tasks it has many limitations. One of which is its Training/Prediction Time. Since the algorithm finds the distance between the data point and every point in the training set it is very computationally heavy. Unlike algorithms like linear regression which simply apply a function to a given data point the KNN algorithm requires the entire data set to make a prediction. This means every time we make a prediction we must wait for the algorithm to compare our given data to each point. In data sets that contain millions of elements this is a HUGE drawback.
Another drawback of the algorithm is its memory usage. Due to the way it works (outlined above) it requires that the entire data set be loaded into memory to perform a prediction. It is possible to batch load our data into memory but that is extremely time consuming.
Summary
The K-Nearest Neighbor algorithm is very good at classification on small data sets that contain few dimensions (features). It is very simple to implement and is a good choice for performing quick classification on small data. However, when moving into extremely large data sets and making a large amount of predictions it is very limited.
In the next tutorial we will implement this algorithm.